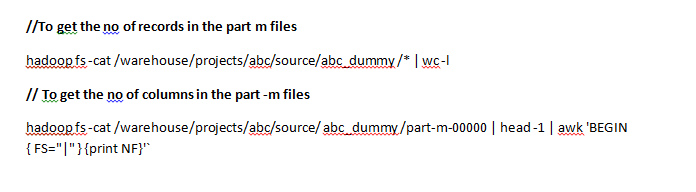
Abinitio on unix to sqlserver on windows conn requirements
This article details the steps required to connect from abinitio on linux ot sqlserver on windows where the sqlserver is kerberos enabled.
This article details the steps required to connect from abinitio on linux ot sqlserver on windows where the sqlserver is kerberos enabled.
Step 1 :
Install 64 bit unix odbc drivers (unixODBC-2.3.0)
Once installed check the below path
/apps/abinitio/abinitio-V3-3-2-1/misc/64/unixODBC-2.3.0/
Step 2:
Install mssqlodbc_V11
Once installed check the below path
/apps/sqlserver/client/native/11.0/lib/
Step 3 :
/etc/krb5.conf
Should contain
---------------------------------------------------------------
######################################################
# krb5.conf - Network Configuration File
######################################################
[libdefaults]
default_realm = INTRANET.abc.COM
default_tkt_enctypes = xxx-xx-xxx xx-xxxx
default_tgs_enctypes = xxx-xx-xxx xx-xxxx
dns_lookup_kdc = false
dns_lookup_realm = false
[realms]
INTRANET.abc.COM
= {
kdc = intranet.abc.com
master_kdc = intranet.abc.com
default_domain = INTRANET.abc.COM
}
INTRANET = {
kdc = intranet.abc.com
master_kdc = intranet.abc.com
default_domain = intranet.abc.com
}
[domain_realm]
.intranet.abc.com = INTRANET.abc.COM
intranet.abc.com
= INTRANET.abc.COM
-------------------------------------------------------------------------------------
Step 4 :
Request has to be raised to make sqlservers Kerberos
enabled (to authenticate cross platform clients)
SPN have to be registered
Step 5:
Test the connection using sqlserver client (which gets installed
as part of step 2)
Go to > cd /apps/sqlserver/client/native/11.0/bin/
Ex command :
sqlcmd -E
-S servername,portno -d master -q "select name from sys.databases"
-E :implies
trusted connection ( takes the credentials from keytab), no need of giving user
name and password explicity
-S : server
name
-d :
database name
-q : query
unfortunately
: if this does not work , plz change the
/apps/sqlserver/client/native/11.0/krb5.conf as in the step 3
Author : Venkata Krishnan P
Author : Venkata Krishnan P